Virtual Cancer Therapist (VCT): towards an In Silico Drug Screening Standard
Introduction
Cancer is an extremely complex process that involves many different protein pathways. For example, two genes, BCL2 and BAX are competing in a cancer cell. BCL2 is an apoptosis-suppressing gene that prevents cell death; on the other hand, BAX is an apoptosis-promoting gene that promotes cell death. When a drug is given to the patient to up-regulate the activity of BAX, it might not be effective since the competing gene BCL2 is suppressing apoptosis. Therefore, a “cocktail” approach, which consists of a chemical to promote the BAX gene expressions and another chemical to suppress the BCL2 gene expressions, is required to control the tumor growth. Unfortunately, since there are thousands of different chemicals and protein pathways that are associated with cancer, it is a very challenging task even for a cancer specialist to identify the optimal combination of different chemicals to cure cancer. Nevertheless, computers can handle data-intensive search operations, such as this one, much faster and more accurate than its human counterparts do. This project proposes the Virtual Cancer Therapist (VCT), a scalable and robust software framework that utilizes Artificial Intelligence and mathematical oncology techniques to identify the optimal combination of anti-cancer chemicals and to simulate the efficacies of the therapy plans in silico.
Other than being a clinical decision-support system, VCT can also be used to establish an in silico drug discovery standard. Currently, the average time-to-market for a new drug is 15 years and on average it costs $0.5 billion. For every 5000 compounds filed for FDA drug application, only one drug makes its way to market. Therefore, a large portion of time and investment is wasted on the chemicals that eventually do not work. This cost can be dramatically reduced if an in silico trial standard is established. VCT is perfectly fit for this task. As VCT operates, more and more patient records, which contain detailed cancer information, are added to the patient record database. Thus when a new drug is proposed, it can be tested against virtual patients (from the patient record database) with different phenotypes and genotypes through the VCT simulation core at a very low cost. These simulation results can then be used to decide whether the drug should go to clinical trials or not.
VCT Architecture
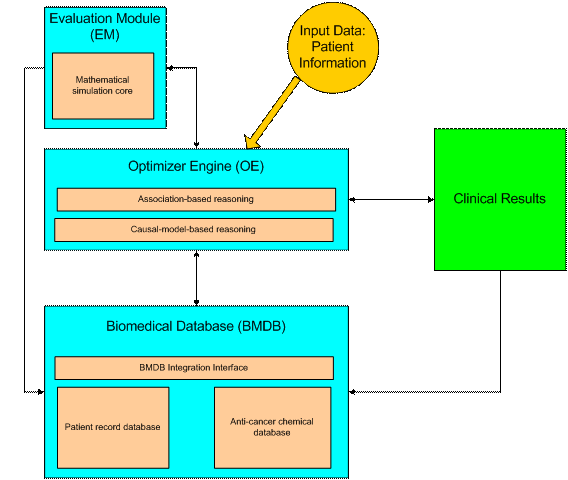
Figure 1: VCT system architecture
As shown in Figure 1, the system architecture of VCT consists of three main modules: an integrated biomedical database (BMDB), an optimizer engine (OE), and an evaluation module (EM).
Biomedical database
(BMDB)
In order to support the cancer expert system, a highly-integrated database that stores complete and accurate biomedical data is required. In this design, BMDB consists of two databases: the patient record database and the anti-cancer chemical database. The patient record database serves two purposes. First, it stores a patient’s cancer medical information as part of the patient’s overall medical record. A patient’s digital medical data records are usually distributed among several hospitals and have different data formats, thus it is very hard to retrieve. To address this problem, the cancer patient records in VCT are stored in the XML format so that they can be easily transformed into other data formats. Second, this information serves as the “experiences” of VCT, which can be used to support the association-based reasoning discussed in the next section. The anti-cancer chemical database stores the anti-cancer drugs’ pharmacodynamic information, such as drug toxicity and drug targets. It is used to support the therapy plan queries initiated by the optimizer engine.
Optimizer engine (OE)
Each cancer case is usually associated with genetic disorders that can be revealed from lab tests. Based on his/her experiences and knowledge, an oncologist makes diagnostic decisions according to the findings he/she gets. This project attempts to solve the therapy selection problem using hybrid reasoning that makes use of association-based reasoning (experiences) in conjunction with causal-model-based reasoning (knowledge). Association-based reasoning is efficient because it makes diagnostic decisions based on past experiences. However, it is not robust since it cannot deal with previously unseen cases. On the other hand, although not efficient, causal-model-based reasoning makes diagnostic decisions based on the complicated cancer diagnosis protocols, thus it is robust. By combining these two methods, VCT has the potential of solving complex cancer problems in a robust and efficient way.
Evaluation module
(EM)
EM simulates tumor growth and chemotherapies by applying the mathematical biology approaches developed by Cristini et al. These models are developed by incorporating parameters obtained from in vitro and in vivo cancer invasion and drug response experiments into the mathematical equations that are used to describe the behaviors of cancer. Especially, the multi-scale, multidimensional tumor simulator has the capability of showing cancer progression through the stages of diffusion-limited dormancy, vascularization and rapid growth, and tissue invasion. In addition, this model has also been successfully used to simulate the delivery of anti-cancer chemicals into tumors.
After a cancer patient’s data is inputted into VCT, these three modules cooperate in the following steps:
- OE processes the input data, makes a diagnostic decision, and formulates queries to search BMDB for the optimal therapy plan.
- OE passes the therapy plan and the patient’s information to EM, which makes a tumor growth prognosis and a simulation of the therapy plan.
- The simulation results are passed to the oncologist. After the clinical trials, clinical results are returned to OE. With machine learning approaches, the simulation and clinical results may be utilized to optimize the query engine and the simulation core. This will be addressed in future projects.
- The simulation and clinical results are stored in BMDB.
From VCT to an In Silico Drug Screening Standard
Two main features, the mathematical simulation core and the patient record database, of VCT enable it to become an in silico drug screening standard. In the ideal case, each oncologist is equipped with a VCT to help him/her identify the optimal therapy plans for his/her patients. As a result, the patients’ detailed information, such as cancer type, tumor size, cancer genotype, etc. gets stored in the local patient database of the VCT. By utilizing distributed computing approaches, these pieces of detailed patient information can be easily accessed by a central server (another copy of VCT). As a result, when a new anti-cancer chemical is discovered, its mechanism can be simulated at the central server against different patient records collected from different distributed copies of VCT. Since different anti-cancer drugs might target at different populations, the central server can extract patient records from VCT copies in a specific region only, thus further improving the accuracy and efficiency of the drug screening process.

References:
Prototyping Virtual
Cancer Therapist (VCT): A Software Engineering Approach
![]()
Shaoshan Liu, Jean-Luc Gaudiot, and Vittorio Cristini
Proceedings of the 28th Annual International Conference IEEE Engineering in
Medicine and Biology Society (IEEE EMBC 2006), New York City, USA, August
30-September 3, 2006
(this paper
contains the detailed information about the design of VCT and all relevant
references)
Distributed Virtual Cancer Therapist (DVCT): towards an In Silico Drug Screening Standard (in prep)
For more information regarding to tumor growth simulations