| PASCAL |
Speculative Execution Model for GPGPU:
Introduction
Unlike the typical CPU, a GPU is specialized in data-parallel computations where hundreds of threads can simultaneously execute the same set of instructions on independent pieces of data. However, because of its optimized architecture design, a GPGPU suffers from synchronization problems which prevent its general use. Even though some techniques may help reduce or even suppress the usage of synchronizations, they are not always practical and often add significant complexity to the programming step. Complex dependency patterns also affect the performance by reducing the chances of parallelism.
Modern computation needs are already well within the Peta range, and some applications are even approaching the Exa scale. To satisfy these future demands, the enormous computing power which GPGPUs may yield will be quite important. The problem is how to exploit this potential and enhance the utilization and programmability of GPGPUs
Goals and Approach
We have observed that some important workloads not only have much intrinsic data parallelism, but also plenty of redundancy of data values, so value prediction can open a chance to the issues of synchronization. Therefore, we are working on the following tasks:
Results
As a first step, we observed the characteristics of workloads which are frequently used in the benchmark suits. Traditionally, data level parallelism of workloads has been the target of parallel processing. The limit is the degree of synchronization, as we have seen with Amdahl’s law. Our observation is there are abundant redundancy of data in the workloads, and in many cases, because of redundancy, the dependencies can be predicted accurately and frequently. We measured the degree of predictability using Bayes’ Theorem.
| Routine | BBL | Routine | BBL | Routine | BBL | |||
| Barnes | 0.95 | 0.76 | Radix | 0.97 | 0.90 | Canneal | 0.63 | 0.79 |
| Radiosity | 0.91 | 0.47 | Raytrace | 0.98 | 0.79 | Dedup | 0.73 | 0.95 |
| FFT | 0.88 | 0.61 | Volrend | 0.84 | 0.86 | Facesim | 0.68 | 0.69 |
| FMM | 0.88 | 0.77 | Swaptions | 0.82 | 0.83 | Fluidanimate | 0.83 | 0.85 |
| LU | 0.96 | 0.69 | Bodytrack | 0.73 | 0.84 | Freqmine | 0.70 | 0.78 |
| Ocean | 0.96 | 0.72 | Blackscholes | 0.89 | 0.88 | Streamcluster | 0.29 | 0.86 |
<Table 1: Routine and basic block (BBL) level regular data predictability>
Table 1 shows the results of predictability with our suggesting prediction scheme. More details can be found in [2].
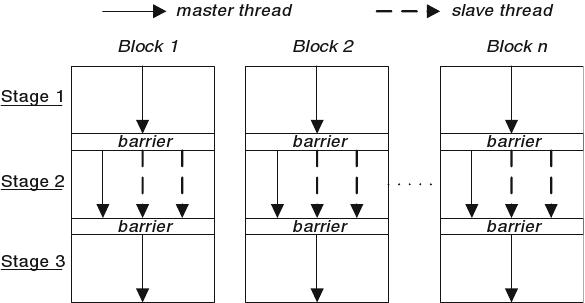
<Figure 1: Value Prediction model on GPGPU>
The next stage was to bring our idea into real world. Figure 1 depicts overall structure of our speculative execution model to overcome synchronization problem on GPGPU architecture. Loop carried dependencies were our first target. The code in the loop can be expressed as computation kernels, and they will be mapped in stage 2 of our frame work. Prediction is made in the stage 1, and evaluation is made in stage 3.
![]()
<Figure 2: transform_PRED performance>
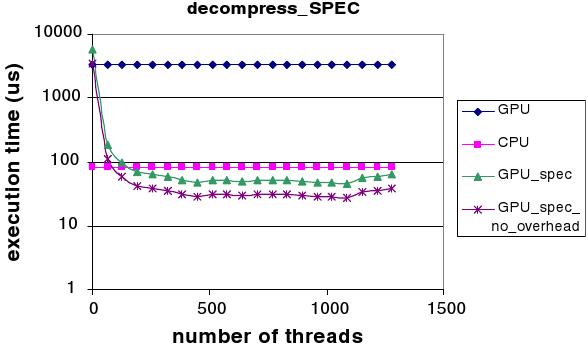
<Figure 3: decompress_SPEC performance>
Here are some results of our framework. In Figure 2, transform_PRED is a loop selected from fp_tree of freqmine in PARSEC. In Figure 3, decompress_SPEC is a loop in the decompress routine inside bzip2 of SPEC 2006. The two workloads shows different degree of intrinsic parallelism, but our frame work, especially in Figure 3 with abundant dependencies, helps the workload to get benefit from GPGPU architecture. More details and results can be found in [1].
Current Status
Still, our framework is experimental stage under the consideration with programming interface. We are extending this framework into a more productive stage so that can be used and tested with more general workloads.
Publications
[1]
Speculative Execution on GPU: An Exploratory Study ![]()
Shaoshan
Liu, Christine Eisenbeis and Jean-Luc
Gaudiot
Proceedings of the Thirty Ninth International
Conference on Parallel Processing, San Diego, California, September 13-16, 2010
[2]
A
Theoretical Framework for Value Prediction in Parallel Systems ![]()
Shaoshan
Liu, Christine Eisenbeis and Jean-Luc
Gaudiot
Proceedings of the Thirty Ninth International
Conference on Parallel Processing, San Diego, California, September 13-16, 2010
[3]
Value Prediction in Modern Many-Core Systems ![]()
Shaoshan
Liu (Ph.D. Student) and Jean-Luc Gaudiot (Advisor)
Proceedings of the 23rd IEEE
International Parallel & Distributed Processing Symposium (IPDPS 2009), TCPP-Ph.D.
Forum, Rome,
Italy, May 25-29, 2009
Lab Equipment
| Specification of C1060 | Description |
| Chip | Tesla T10 GPU |
| Processor Clock | 1296 MHz |
| Memory Clock | 800 MHz |
| Memory size | 4 GB |
| Stream Processor Cores | 240 |
| Peak Single Precision Floating Point Performance | 933 GFlops |
| Peak Double Precision Floating Point Performance | 78 GFlops |
| Memory Bandwidth | 102 GB/sec |

| Specification of C2070 | Description |
| Chip | Tesla T20 GPU |
| Processor Clock | 1.15 GHz |
| Memory Clock | 1.50 GHz |
| Memory size | 6 GB |
| Stream Processor Cores | 448 |
| Peak Single Precision Floating Point Performance | 1.03 TFlops |
| Peak Double Precision Floating Point Performance | 515 GFlops |
| Memory Bandwidth | 144 GB/sec |

Copyright © 2011 PASCAL — All Rights Reserved