Network-based computing[1-5,10] has been considered as an economical alternative to supercomputing. In network-based computing, workstations connected by a general-purpose network function as a large-scale distributed system and provide a transparent interface to the user. However, traditional design of computer architecture did not consider the communication requirement as the first priority. Communication between workstations involves excess software/hardware overhead. The introduction of high-speed networks such as ATM dramatically increases the network bandwidth but the software/hardware overhead incurred on the network interface is not reduced. Without architectural support, network-based computing is only applicable to coarse grain applications.
II. Goal and Approach
It is crucial to identify and solve the communication bottlenecks to make network-based computing more useful. Our previous studies, with experiments on a network of workstations[6], have identified the bottlenecks and we have proposed a new communication architecture[8], including network interface design, low-level messaging layer and a set of application programming interface(API), to solve these problem.
Since architectural changes are expensive and time-consuming, simulation is adopted to verify our communication architecture. We chose PAINT[7] as the base simulator and implemented our proposed communication architecture on it. Microbenchmarks and macrobenchmarks are used to measure the performance. Microbenchmarks include simple applications to test the end-to-end communication latency and deliverable bandwidth. Macrobenchmarks contain a set of scientific applications, e.g. Numerical Aerodynamic Simulation suites, to demonstrate the performance for parallel processing.
III. Performance
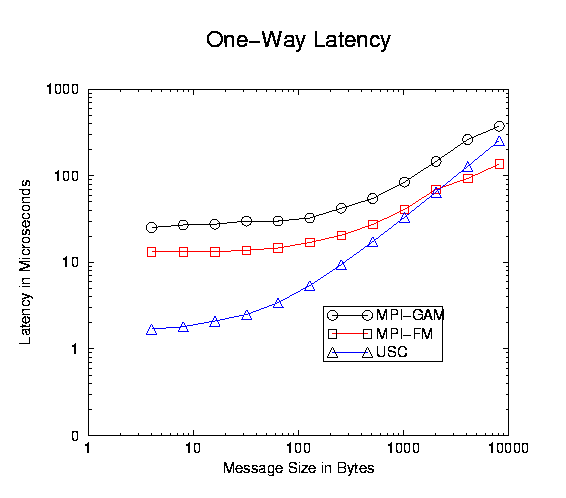
We have derived preliminary performance numbers for point-to-point communication and collective communication [9]. The following figure shows the application level one-way latency between two nodes. Our result is compared with two other fast messaging softwares: MPI-GAM and MPI-FM, which are MPI implementations based on Generic Active Messages[1] and Fast Messages[3] respectively.
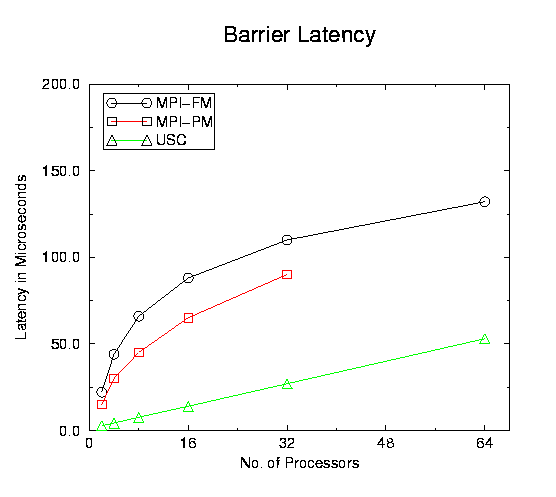
Our simulation for microbenchmarks has shown better performance than other fast messaging softwares. Currently, we are implementing some macro-benchmark applications and will use them to further demonstrate the advantages of our communication architecture.
V References
[1]D. Culler etc.,"Parallel Computing on the Berkeley NOW," Ninth Joint Symposium on Parallel Processing, 1997.
[2]T. v. Eicken and A. Basu and V. Buch and W. Vogels, "U-Net: A User-Level Network Interface for Parallel and Distributed Computing," Proceedings of the 15th ACM Symposium on Operating Systems Principles, December 1995.
[3]S. Pakin and M. Lauria and A. Chien. "High Performance Messaging on Workstations: Illinois Fast Messages(FM) for Myrinet," Supercomputing'95
[4]A. Chien,S. Pakin, M. Lauria, M. Budanan, K. Hane and L. Giannini , "High Performance Virtual Machines (HPVM):Clusters with Supercomputing APIs and Performance," Eighth SIAM Conference on Parallel Processing for Scientific Computing.
[5]C. Dubnicki, L. Iftode, E. W. Felten, and K. Li. "Software Support for Virtual Memory-Mapped Communication," International Parallel Processing Symposium, April 1996.
[6]Grant from the IBM Strategic University Research (SUR) Program, 1996 and 1998.
[7]L. Stoller, M. Swanson and R. Kuramkote. "Paint: PA Instruction Set Interpreter,"Technical Report UUCS-96-009, Department of Computer Science, University of Utah.
[8]Chung-Ta Cheng "Architectural Support for Network-based Parallel Computing," Ph.D. Dissertation Proposal, May, 1998.
[9]Chung-Ta Cheng and Jean-Luc Gaudiot "Architectural Support for Network-based Parallel Computing," Submitted to PACT'99.
[10]Hiroshi Tezuka, Atsushi Hori, Yutaka Ishikawa and Mitsuhisa Sato. "PM: An Operating System Coordinated High Performance Communication Library," High-Performance Computing and Networking, Volume 1225 of LNCS, April, 1997.